

摘要:OpenAI采用自我博弈强化学习技术路线进行深度推演,通过智能体自我对抗,不断优化策略,提升智能水平。该技术路线涉及复杂系统建模、机器学习算法设计及优化等方面,旨在实现更高效的智能体学习机制。该路线具有广阔的发展前景和实际应用价值,将为人工智能领域带来新的突破。
目录导读:
开篇概述
随着人工智能技术的飞速发展,强化学习(Reinforcement Learning, RL)已成为研究的热点领域,OpenAI作为人工智能领域的领军者,其推出的自我博弈强化学习技术路线备受关注,本文将深入探讨OpenAI o1自我博弈强化学习的技术路线及其未来发展。
OpenAI与自我博弈强化学习
自我博弈强化学习是一种通过智能体与环境交互,自主学习和改进的策略学习方法,OpenAI致力于此领域的研究,不断取得突破性进展,其核心技术包括策略优化、模型训练等方面,为人工智能的发展提供了强大的技术支持。
三、OpenAI o1自我博弈强化学习技术路线解析
OpenAI o1自我博弈强化学习技术路线的核心在于自我学习与自我优化,其技术路线可概括为以下几个阶段:
1、数据收集与处理:通过大量数据收集,为模型训练提供基础数据。
2、模型训练:利用深度神经网络进行模型训练,提高模型的智能水平。
3、自我博弈:智能体通过自我博弈,生成新的数据用于模型再训练。
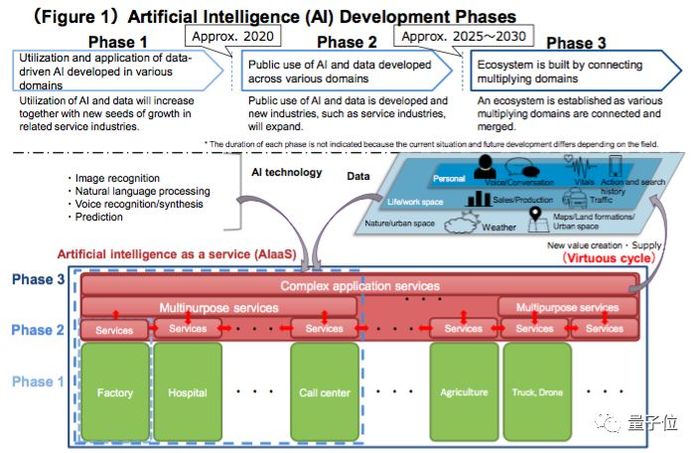
4、策略优化:根据博弈结果,优化智能体的策略,提高其在环境中的表现。
5、迭代更新:不断重复以上步骤,实现智能体的自我学习与优化。
技术挑战与解决方案
在OpenAI o1自我博弈强化学习的技术路线中,面临的主要挑战包括:
1、数据处理与标注:大量数据的收集与处理是强化学习的基础,需要解决数据标注等问题。
2、模型训练效率:提高模型训练效率,加快智能体的学习速度。
3、策略优化难度:在复杂的博弈环境中,策略优化是一大挑战。
针对以上挑战,OpenAI提出了以下解决方案:
1、利用无监督学习进行数据处理,减少人工标注的成本。
2、采用分布式训练技术,提高模型训练效率。
3、结合深度学习与决策树等算法,优化策略表现。
技术应用与实例分析
OpenAI o1自我博弈强化学习技术已广泛应用于多个领域,如游戏AI、机器人等,以游戏AI为例,通过自我博弈强化学习,智能体可以在游戏中自主学习和改进,最终超越人类玩家的水平,在机器人领域,自我博弈强化学习技术可使机器人实现自主导航、物体识别等功能。
未来发展趋势预测
随着技术的不断进步,OpenAI o1自我博弈强化学习未来将呈现以下发展趋势:
1、技术融合:结合深度学习、计算机视觉等技术,提高智能体的感知与决策能力。
2、场景拓展:将自我博弈强化学习技术应用于更多领域,如自动驾驶、智能家居等。
3、实时性优化:提高模型训练的实时性,加快智能体的响应速度。
OpenAI o1自我博弈强化学习技术路线的成功实践为人工智能领域带来了革命性的突破,随着技术的不断进步与应用领域的拓展,OpenAI o1自我博弈强化学习将在更多领域发挥重要作用,我们期待这一技术在未来能够带来更多惊喜与突破。
八、互动与讨论环节邀请大家留言讨论关于OpenAI o1自我博弈强化学习的看法以及未来的期待!让我们一起探讨人工智能的未来发展!
转载请注明来自徐州满江红科技有限公司,本文标题:《OpenAI o1自我博弈强化学习技术路线深度推演》










 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号